



The First 100% Copyrighted AI Data Training Set (+Meta AI Data Privacy Scandal)
Cheating confessions, cancer treatments, home addresses, and explicit questions. User prompts thought private were published to Meta AI's public feed. Here's how to make sure your data is safe.

Meta’s AI app is exposing people’s cheating confessions, legal battles, and medical records… publicly.
We’re talking real names. Real screenshots. Home addresses. Voice notes. All showing up in the app’s public feed. Don’t believe me? Here’s an example.
“What countries [sic] do younger women like older white men,” a public message from a user on Meta’s AI platform says. “I need details, I’m 66 and single. I’m from Iowa and open to moving to a new country if I can find a younger woman.”

The wild part is most users have no idea that they’re broadcasting their lives on the internet.
Today I’m breaking down how this turned into one of the worst AI privacy fails we’ve seen so far, and yes, Meta didn’t make it easy, but scroll to find a step-by-step guide to navigate their buried settings and protect your data before more is exposed.
If you’ve ever used AI like a diary and now feel a sudden wave of panic, hit subscribe. Don’t worry, I got your back.
We’ll also cover the other major AI updates you need to know — including how OpenAI just took a real step toward actually helpful AI agents with the launch of a new model O3 Pro, and the release of the first-ever AI training dataset built entirely from licensed, legally verified content.
Update 1 - Meta AI App Data Privacy Crisis
So people are accidentally leaking their medical records, affairs, and desperate dating strategies, straight into the public feed of Meta’s new AI app.
And they have no idea they’re doing it.
The app lets users share their conversations with Meta AI publicly, but a lot of folks, especially older users, think they’re using a private journal. Instead, they’re broadcasting their lives to a public feed called Discover. The result? These are real, guys.
A 66-year-old asking, “What countries do younger women like older white men?”
Cheating confessions with full names and screenshots
Veterinary bills showing home addresses
Legal battles spelled out in full, asking how to adjust death sentence pleas
Medical information such as cancer treatment protocols
You can’t make this up. Just raw personal data posted accidentally for the world to scroll through. And while Meta says posts are only shared if users tap through a specific “share” process, clearly they didn’t dummy proof the process enough. Because people think they’re talking to a private assistant — not publishing to a social feed.
Even Meta’s own AI commented:
“Some people don’t read the fine print.”
Yeah, no kidding.
Real talk guys, how many of you feel you’ve shared a bit of personal information with a chatbot, used it as a therapist, maybe fed it you shouldnt? Or do you feel you know not to do that?
Okay — here’s how to shut it off. For yourself… or for the sake of protecting your uncle’s bank account information might end up on Meta’s Discover tab. Make sure to take a screenshot.
🔧 Step-by-step
Tap your profile photo in the top-right corner of the Meta AI app.
Scroll down and hit “Data and Privacy.”
Under “Suggesting your prompts on other apps,” find each app listed (like Facebook and Instagram) and toggle it OFF.
But you’re not done.
Go back to the main Data and Privacy screen.
Tap “Manage Your Information.”
Click “Make all your public prompts visible only to you,” then hit “Apply to All.”
Want to erase the cringe? This is also where you can delete your entire prompt history.
Update 2: OpenAI O3 Pro is a Model for AI Agents
There’s a new model release this week — and it’s not another chatbot you vent to about your boyfriend. It’s the one your boss is about to integrate to finally make AI agents possibly actually work.
OpenAI just dropped O3 Pro. Yes, another model. Cry. But this one’s different because it’s not built for casual chat anymore.
It’s built for what agents are supposed to be doing: deep reasoning, tool use, and long-context tasks. Think less “fun facts about sea otters” and “why isn’t my boyfriend responding to my texts”, and more “generate a full product roadmap from these 14 meeting transcripts.”
So you see the potential, right?
Now here’s the funny part: I was Googling “O3 Pro” to prep this episode, and suddenly I see my brother, Ben Hylak, second result on Google with the world’s first public review on
. I didn’t even know he published it. Thanks, Ben.But in his review with co-founder Alexis Gauba, they nail the mindset shift perfectly: O3 Pro works best when treated like a report generator — not a chatbot.

You have to load it with strategy docs, product plans, even voice memos… then ask for analysis. It needs a ridiculous amount of context and structure. The more you give it, the better it performs.
To put that into something visual: how many of you saw the graphic floating around X a few months ago showing the anatomy of a great AI prompt? That graphic was actually made by my brother, and this right here is the updated version, comparing O1 to O3 Pro.
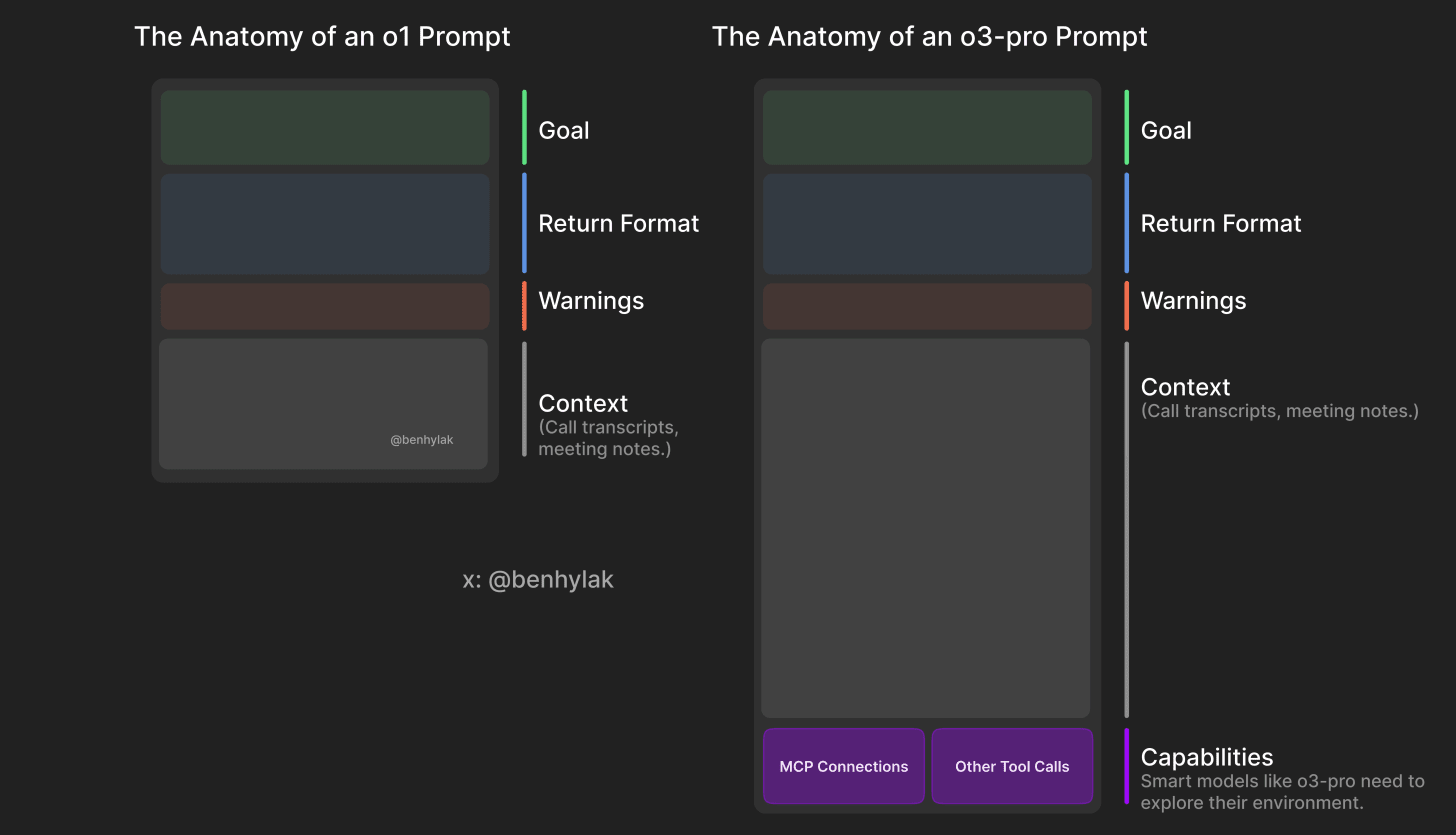
With O3, you give it a goal, a format, maybe some context, and you’re good. But O3 Pro is hungry. It wants call transcripts, meeting notes, tool access, system-level instructions. It WANTS a lot of data to do its best work. It acts more like an agent than a model.
But (there’s always a but), O3 pro is painfully slow. I saw a test where someone just said “hi” to O3 Pro… and it took six minutes to respond. Six. Minutes. To say hi. So yeah… not your go-to for small talk.
Let’s talk performance. When used right, O3 Pro outperforms the base model in over 60% of evaluations. It’s built for planning, analysis, orchestration, making decisions based on messy, real-world inputs. And the price point is high so it reflects that shift: OpenAI is clearly moving from “chatbots for all” to specialized intelligence, tailored to the task.
So if O3 is your generalist… O3 Pro is your first major step towards AI agents. IT’s just built to think and act more like a teammate than the past models.
Do you guys think O3 pro will actually help towards the development of AI agents or just another release?
Update #3: First AI Training Dataset on 100% Licensed Data Launched by EleutherAI, HuggingFace, and MIT
For years, the narrative’s been the same: “We had no choice. To build advanced AI, we had to scrape the web. Copyright? Ethics? We’ll figure that out later.” But this week that story was thrown in the garbage as the first major AI training dataset built entirely on licensed and legally vetted content was released.
It’s called Common Pile, an 8-terabyte dataset created by EleutherAI with a monster list of collaborators like Hugging Face, MIT, and Cornell. It took them two years to build it and filter out anything remotely questionable, even rejecting the most popular datasets used by the major AI companies like OpenAlex or Youtube Commons because they couldn’t confirm the licenses were clean.
No gray zones. No guesses. Every single piece of data was either directly verified with the rights holder or pulled from crystal-clear public domain sources. Which is super noble, but I know what you’re thinking: Okay Veronica, how does it perform?
Turns out? Shockingly well.
Early benchmarks show that models trained on this clean data perform nearly as well as models trained on scraped content, sometimes even better. We were told that this wasn’t possible. Turns out, it is.
Now, I know people are going to have mixed reactions. Some will say, “See? The companies always lied!” Others will say, “They didn’t know. They were experimenting!” And honestly? Both are a little true. The early wave of generative AI moved fast without clear rules. But that’s what makes this release so important: Common Pile just proved that ethical data can perform AND scale.
And lets be honest, almost every major AI company today is facing lawsuits about how they trained their models. Like Look at some of those lawsuits. Oof. Governments, institutions, even enterprise buyers can’t afford that kind of legal fog long term.
So this gives us a playbook on how to move forward.
If youre on the technical side and want to see their super impressive pipeline that they used to clean the data, I’ll link the paper in the description.
Everyone else: what do you think, do you think long term building AI models on purely legally vetted data is feasible or do you think that stuff on the internet is up for grabs?
Update #4: SPEED ROUND
Apple WWDC
Apple completely flopped at this year’s WWDC. Last year they hyped up “Apple Intelligence” like it was going to change everything. This year? Barely a whisper. Instead, they gave us “Liquid Glass,” a shiny new UI design that is trying so hard to look cool (but fails), and is kind of an accessibility nightmare.

I’m not even 30 and I can’t read my phone anymore. Some people think it’s Apple conditioning us for future spatial computing devices (like visual prep for Vision Pro 2) but I think that’s total BS. I just have a question, How is X beating Apple in the AI race, like that’s not a sentence I thought I’d ever say.
Apple keep making decisions like this and I’m going to strongly be looking for an alternative... If you agree, subscribe.
Anthropic AI Blog
Anthropic’s fully AI-written blog is dead. It was meant to flex Claude’s writing skills, but apparently no one wanted to read a blog with zero human voice. I just found this one hilarious. Humans keep fighting.
Vaccine Website
A U.S. government vaccine website has been defaced and is now hosting what appears to be AI-generated spam, including, yes, furry p*rn. I’m super uncomfortable, are you uncomfortable? I dont want to report this news It’s run by the Department of Health and Human Services, and no one knows who did it or why… but it's definitely not about vaccines anymore.
Update #4: Tiktok/Bytedance Launch Document Parsing Model Dolphin
Last but not least, a new model by the company that owns Tiktok, Bytedance.
If you’ve ever tried converting PDF into something actually usable... you already know: it's 2025, we’re in the age of AI, but apparently we still can’t seem to figure out document parsing.
But bytedance might’ve just fixed your enterprise PDF nightmare.
This one’s a little more technical so best suited for devs, but it’ll also be helpful for anyone whos fought with file layout issues, OCR, or 17 versions of the same Word file.
Iykyk.
Bytedance just launched a new multimodal document parsing model called Dolphin, taking a fresh approach to one of the oldest annoyances in enterprise tech: converting complex documents into structured, readable content without destroying the layout.
ByteDance says current approaches break down when documents get too complex, or become too inefficient to scale both for traditional OCR or even advanced Vision Language Models (VLMs).
Dolphin claims to have fixed this issue with a two-stage “analyze-then-parse” flow. First, it analyzes the full page using Swin Transformers to extract layout elements in proper reading order.
Quick aside, Swin Transformers, short for Shifted Window Transformers, are a visual model architecture from Microsoft that breaks the image into small windows and processes them locally instead of overwhelming the system by analyzing the full page at once. It’s like scanning the page through a smart magnifying glass, piece by piece.
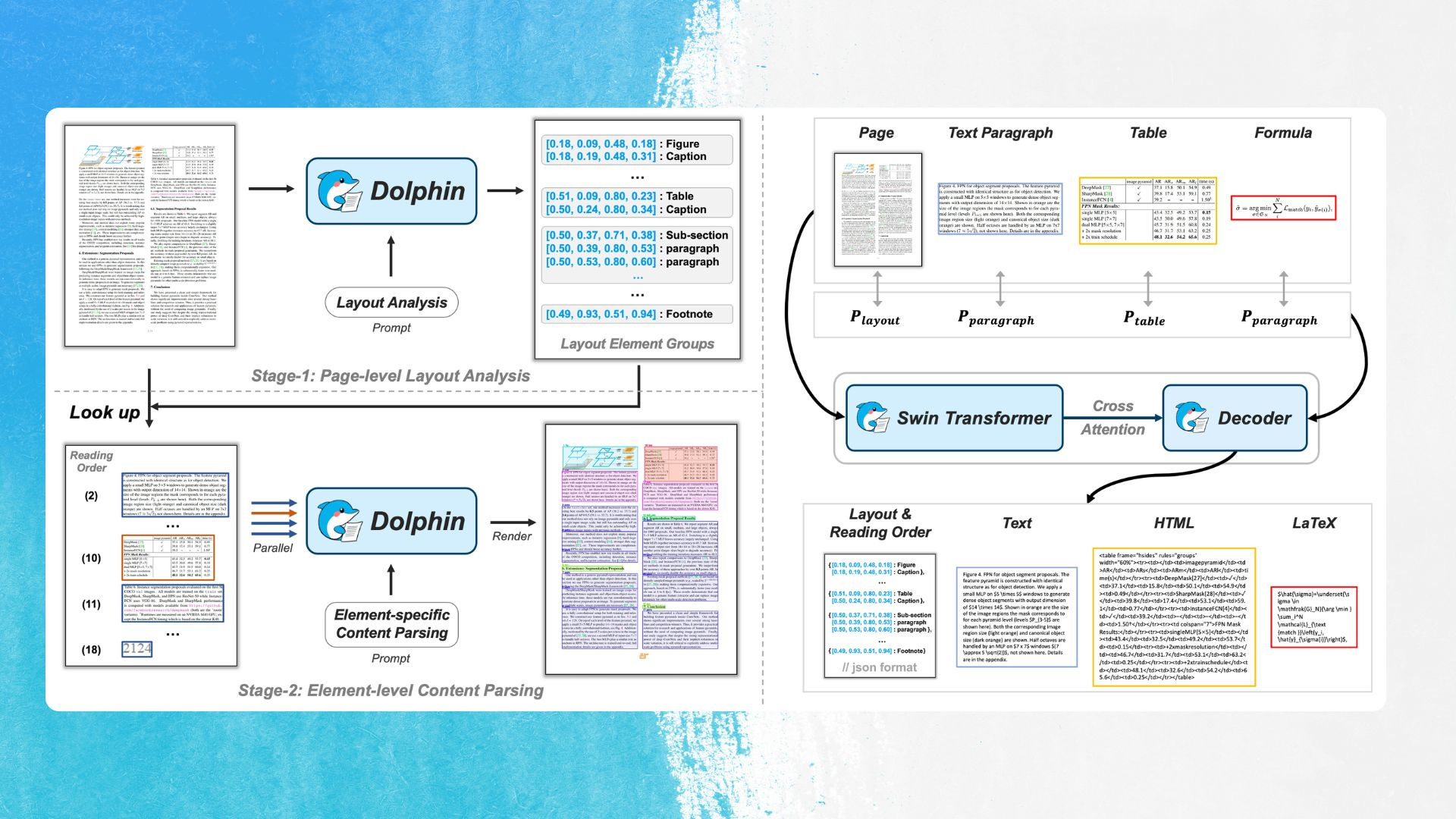
This helps Dolphin identify structure (think headers, tables, formulas) and map everything using prompts like: “Parse the reading order of this document.” Then, each element is cropped out, encoded locally, and parsed in parallel with tailored prompts, which makes the whole process both faster and more accurate.
It’s not perfect, but it’s a glimpse of a future where document workflows don’t require duct-tape solutions and eight different APIs just to get one clean output. So maybe, finally, we're getting closer to a world where parsing a document doesn’t feel like performing surgery with a butter knife.
Appreciate you spending these few minutes with me, please remember to like comment and subscribe, i love reading your thoughts i read every single one.
Thanks so much.
Ben is one of our fave guest authors ever!!! invited back any time.
sounds like the Hylak fam has strong writer genes...