



Devin AI Launches: The AI Developer Assistant Breaking New Ground (and Occasionally Its Own Code)
This week in AI: Devin AI launches, Google's algorithm update penalizes AI content, outdated performance benchmarks questions, India's government to regulate AI models, and an OpenAI-Musk speed round.

Watch the video de-briefing if you don’t have time to read 😋
Advancement #1: The alleged first AI software engineer “Devin” launches
In a groundbreaking leap for the tech world, Cognition unveiled "Devin" - the first-ever fully autonomous AI software engineer, capable of writing, deploying, and debugging complex codes with just a single prompt.

Setting the stage for what could be considered the future of coding, Devin stands out by taking on end-to-end development responsibilities, something that previously existing AI coding assistants like OpenAI's Copilot couldn't achieve. All commands are currently conducted through a standard chat interface, and you can watch the demo video here.
Here’s a breakdown of the capabilities that set Devin apart:
Code Generation and Deployment: Devin can write and deploy complex code snippets, entire applications, or websites from just a single prompt. This includes generating the source code, configuring databases, setting up server-side logic, and ensuring the application is ready for deployment.
Error Detection and Debugging: Unlike traditional coding assistants, Devin goes a step further by scanning for errors in the code it produces. More impressively, it can identify compilation issues, logical errors, and even subtle bugs that might elude human programmers, automatically correcting them without external intervention.
End-to-End Development Responsibilities: Devin is engineered to handle the full spectrum of development tasks. This encompasses planning, executing complex engineering tasks, and utilizing common developer tools like code editors and web browsers—all autonomously.
Real-Time Progress Monitoring and Testing: Users can receive updates on project progress in real-time. Devin also conducts tests on its own work, ensuring that the software or website functions as intended before deployment.
AI Model Fine-Tuning: For developers focused on enhancing AI models, Devin offers capabilities for fine-tuning existing AI models. This can involve optimizing models with the latest algorithms or technologies based on specific developer requests or reference materials.
Debugging Major Repositories: Devin isn't limited to working on new projects. It can also delve into existing repositories, identifying and fixing a wide range of errors—from syntax issues to complex logical faults.
Setting Up Real-Time Models: Devin supports the development and deployment of real-time models for a variety of applications, including computer vision and deep learning projects.
Devin’s launch marks a paradigm shift in AI-assisted coding, propelling AI from a supportive role to a leading one. Developers can now leverage Devin to tackle the mundane, freeing up human creativity for more complex, innovative tasks. With current funding of 21 million and a good roster of investors (including ex Twitter), Devin is not currently publicly available and still heavily in their early access period by request only.
My Initial Thoughts: AI code generation tools have a little bit of a sore spot in my heart, only because my brother’s first startup (called Sidekick.dev) attempted to accomplish just what Devin claims. His team decided to abandon the project last October after many VC’s were weary of investing in a tool that the big companies (like Microsoft and Github) were already working on. I am happy to see that Cognition was able to push back through that barrier.
However, I am a little more pessimistic, just because of the lens I have from watching my brother build his.
Primarily, I believe Cognition clearly did an amazing job creating social media buzz with their announcement, but their product to me looks like a badly edited demo video of someone trying to build a product with RAG and chain-of-thought techniques. They don’t appear to have their own model, causing many to speculate it’s just a GPT wrapper. Their website is also absolutely awful, which leads me to the question of if Devin built it or not.
Ultimately, this is a really important announcement to keep up on… but knowing what I know about code generation startups, and the fact that it’s not even publicly available, I’m really not convinced on how great this one actually is compared to what they’re saying. Nonetheless, the article says Devin solved 13% of open GitHub bugs unassisted, which isn’t insignificant (especially considering Claude 2 and GPT were about 4%. That number will only rise from here.
Advancement #2: Google launches new core update that penalizes low-quality content made for search algorithms instead of people
In March, Google initiated a major update to its core search algorithms, aiming to target the surge of low-quality content on the web by significantly down-ranking their result in a SERP (Search Engine Result Page). The focus is on reducing the visibility of pages that are optimized for search engines at the expense of offering creative or highly valuable results to real people.

Notably, Google subtly addresses the issue of AI-generated content without explicitly mentioning AI, opting to use the phrase "content by automation". This choice of words is interpreted by many experts that the update is geared towards penalizing AI-generated content that fails to provide authentic value to users.
Google explains the process of a core update for search engine results as being equivalent to updating a list of your top 100 movies from 2021 in 2024. Newer movies will become eligible for inclusion, and you may find that certain movies deserve a higher ranking than previously assigned.
By emphasizing the crackdown on "content by automation", Google signals its commitment to combating the proliferation of content that, while technically sophisticated, lacks the depth, insight, or originality that users seek.
Google has stated that this update (building off of past ones) will improve search quality by 40%. Their nuanced approach to address AI-generated content comes at a time where researchers have publicly begun to communicate a significant decline in their search quality. This update may assist Google to maintain the integrity and usefulness of its search results.
My Initial Thoughts: I use ChatGPT, a lot (don’t get me wrong). However, I really can’t use it for any kind of content that requires thought or innovation. I even recently started to interview a few copywriters for my startup because of this issue, as I have realized how much of a skill it is to communicate a particular message effectively online.
Many people have seen a decline in respect for sure professions, thinking they could automate most of their content generation by running it through ChatGPT. With this core update, the anti-copywriters are about to get a wakeup call. When their pages are significantly down-ranked because of their low-quality bulk AI content (which will in turn affect their business), they will struggle to gain ground again.
For content creators and website operators, the message is clear: the focus must remain on producing innovative content that is written for people first, not search engines. Google reassures that there are no new or special requirements for this update for those who have consistently focused on creating quality content (and therefore, hints at the fact that you can continue to use AI content of high quality… most likely involving a highly skilled human crafter). Content creators, if you’re still worried, here’s Google’s guide for creating human-first content.
Nevertheless, the update serves as a cautionary reminder of the potential consequences of over-relying on AI for content creation.
Advancement #3: Concerns of Performance Reporting Inaccuracy as Model Performance Benchmarks are 3+ Years Old
When new models are launched on the market (such as last week’s Anthropic release), several graphs with percentage performance metrics comparing the new model to others on the market is released alongside with it. Of course, the logic is simple… how else would you be able to compare the progress of the new model?

Yet amidst these releases, a critical issue has become louder. The benchmarks used to evaluate these models, which are research focused and date back to over three years, predate the invention of modern GenAI tools.
The heart of the problem lies in the disconnect between current benchmarks and real-world application, causing experts to state there is an ongoing "evaluation crisis" within the industry.
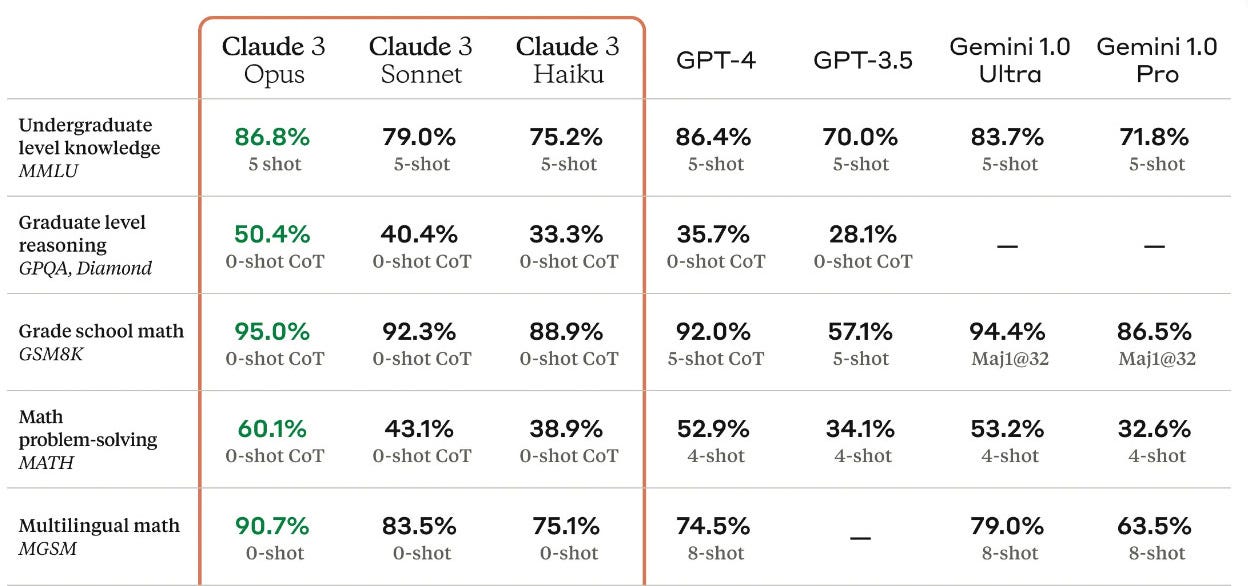
Even in tests supposedly designed to assess general logic and reasoning, many benchmarks are riddled with errors and nonsensical content, further questioning their validity. For example, assessments intended to measure commonsense reasoning (shown in a research evaluation HellaSwag) suffer from a significant number of typos and illogical questions. Similarly, benchmarks such as MMLU, intended to evaluate a model's ability to navigate through logic problems, often reduce to mere exercises in rote memorization rather than genuine understanding.
“[Benchmarks like MMLU are] more about memorizing and associating two keywords together,” David Widder, a postdoctoral researcher at Cornell, stated. “I can find [a relevant] article fairly quickly and answer the question, but that doesn’t mean I understand the causal mechanism, or could use an understanding of this causal mechanism to actually reason through and solve new and complex problems in un-forseen contexts. A model can’t either.”
The misalignment and questionable efficacy exemplifies the urgent need for a benchmark’s to be re-established to more accurately reflect the ways AI models are used today outside of a standard research capacity.
My Initial Thoughts: I was heavily involved in the music scene in New York City before I transitioned into software, specializing in music licensing and copyright. Although it feels like a different lifetime (I not only worked for Sony Music but even attended the Grammy’s), this reminds me of a similar issue the music industry faced around outdated music copyright laws in the era of streaming.

For 15+ years, the entire industry was compensating artists based on copyright law from 1998 that emphasized downloads or outright purchases. As streaming is neither of those things and simply playback time, Spotify was operating in a legal gray zone (to their own benefit) for a good while. This ambiguity allowed Spotify to unilaterally determine the payments to artists, often resulting in minimal compensation rates (approx. 0.006 cents per play but fluctuated at will compared to 9.1 cents earned for a download) until the introduction of the Music Modernization Act in 2018.
Why is this story relevant? While our initial reaction may be to immediately question everything we’ve ever known (and even question the intention of these company’s reporting with older benchmarks), the fact of the matter is this AI benchmark evaluation crisis is nothing new in the history of advancement. Regulatory laws and guidelines take a lot of time to catch up.
Nonetheless, coming across this information this week was very helpful for me to understand that the numbers reported are not necessarily a true reflection of the output I will receive until those benchmarks are updated.
Advancement #4: Speed Round of Multiple Open AI and Elon Musk Mini Updates
There are a lot of mini updates surrounding Elon Musk and Open AI, so I’m going to do a quick speed round as opposed to a full section for each one. Honestly, it’s all you need to know.
Elon Musk announced on X Monday that he will be open-sourcing Grok, his proprietary chatbot by company xAI. As last week I mentioned it was quite hypocritical he was trying to keep OpenAI open-sourced but his own AI was proprietary, this feels like a strategic announcement in order to address some of that backlash. This announcement was made only 11 days after the lawsuit against openAI was filed.

OpenAI responded to Elon Musk’s lawsuit in a public statement written by several co-founders to offer their own narrative on the situation. The post stated that not only did they realize it would take a significant amount of funds to achieve OpenAI’s mission than originally thought, but Elon Musk was aware of a for-profit structure throughout their engagement, and rather wanted “absolute control”.
“As we discussed a for-profit structure in order to further the mission, Elon wanted us to merge with Tesla or he wanted full control,” including “majority equity, initial board control, and to be CEO. We couldn’t agree to terms on a for-profit with Elon because we felt it was against the mission for any individual to have absolute control over OpenAI.”

OpenAI announced the return of Altman to its board of directors after his earlier departure and CEO role termination. Accompanying his return are three new board members: Sue Desmond-Hellmann (former CEO of the the Bill and Melinda Gates Foundation) Nicole Seligman (ex-Sony Entertainment president), and Fidji Simo (InstaCart CEO). Expanding the board to eight members, this change follows criticism of OpenAI's previously all-male board and its lack of diversity.
My Initial Thoughts: OpenAI’s response does shed a different view on the Musk lawsuit. While Musk did seem to be in favor of a for-profit model in past communications, if he didn’t formally agree to the direction that was pursued, it could still *possibly* be a breach of contract. I’ve read opinions that Elon’s credibility will hinge on the fact of whether he can prove GPT-4 achieved AGI or not. In the founding documents allegedly it stated that if AGI was achieved, it would have to be open-sourced.
The rest of the updates were good to stay on top of, but not much to expand on other than general fact sharing.
Advancement #5: India Begins to Regulate AI Models
NOTE: This advisory was reversed in the last 12 hours (March 15) due to the backlash. Because it is still important to know what happened, I am going to include this section. Things are moving so fast… happy to help you stay updated.
India has introduced a significant shift in its approach to artificial intelligence regulation, moving from a previously hands-off stance to requiring government approval for the launch of new AI models. The new advisory also mandates that AI companies label the potential unreliability of their AI outputs and to prevent any bias, discrimination, or threats to electoral integrity. While the Deputy IT Minister Rajeev Chandrasekhar admits this advisory is not currently legally binding, it signals a future of tighter regulation by “strongly encouraging” companies to comply.

The Indian government's advisory on AI came after Chandrasekhar expressed discontent with Google Gemini for its response to a query about Prime Minister Narendra Modi. When asked if Modi was a fascist, Gemini referenced unnamed experts who have accused Modi of enacting fascist-like policies. Chandrasekhar warned Google that such answers breached multiple Indian laws including criminal code, highlighting the government's increasing scrutiny over AI-generated content related to political figures.
While the advisory specifically targets "untested AI platforms deploying on the India internet" and does not apply to startups, the change has alarmed many leaders in the AI space. From startup owners who now feel de-motivated by the regulations to even Aravind Srinivas, co-founder and chief executive of Perplexity AI, many fear it will dampen competitiveness and innovation of AI technology within India.
My Initial Thoughts: Gemini’s output issue strikes again, this time spiraling an entire country’s government to tighten AI regulations for political motivations. Chandrasekhar stated that the response in question was from a month ago (before Gemini’s scandal), so I wonder if he would be content with the responses once Gemini is updated.
In either case, this is a dangerous baby step towards government AI regulation and censorship.
By mandating approval, it introduces a subtle form of potential censorship and control of model outputs under the guise of safety regulation. It's a move that could easily slide into tighter control over AI development and usage, which could in turn further make us question the truth and legitimacy of the outputs even more going forward.
This sort of mandate is the first of its kind from a major country (as far as I’m aware of), so I can only assume more will follow.
Housekeeping
I started a Youtube page to give all of these updates in a video format for those who don’t have time to read (and want to listen in the background). If you could subscribe, it would mean so much. Use the video link embedded above.
